Monday November 13th
Hotswapping Haskell and Probabilistic Programming
-
Jon Coens gave a talk on Haxl’s GHC Linker system. These are notes based on a presentation he gave at Haskell Hackers
-
He comes from a systems engineering background, which I thought was pretty sweet, since that’s what I was interviewing for on Friday, even though I had no idea what it was :)
Their Rule Engine
- determines whether spam or not before touches back-end
Rules of Real Engine
- Large: (supplies Facebook, Instagram, WhatsApp)
- Needs to push frequently: 100 times a day
- Update Quickly: commit in live-time
Why Haskell?
- Type Safety
-
Logic Changes complexity
- He mentioned if they were using C++ they would have seg-faults all day
Fast Updates
- typically you’d use a statically linked binary
- GHCI concept as a server wasn’t performant
- GHCI was compared to Haskell’s runtime by itself
Concept of Hotswapping
- should be able to suck in code the same way a bytestring or text is sucked in
-
Hotswapping shared objects .so or .dll where new version of binary is swapped with old one
- Here is sort of a rough diagram of how it is visualized
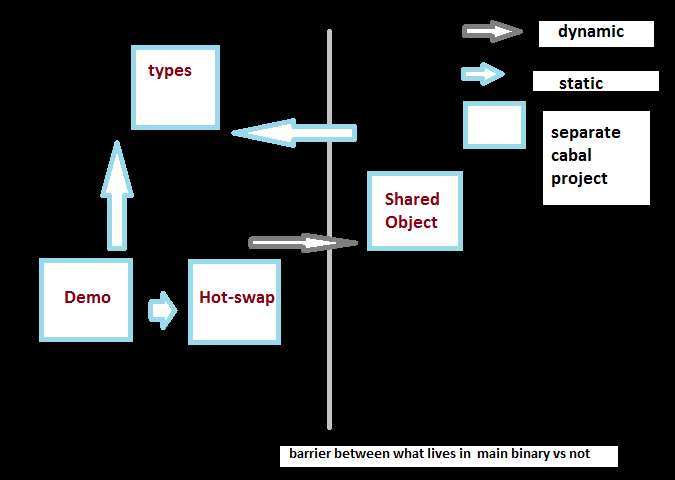
-
dynamic linking : he used an example of taking every instance of “foo” and replacing in binary an object that represents the function you named “foo” in your function
-
Types: describes boundary between main binary and shared object
Haskell code/ repo time
see line 152
unless resolved $ do
unloadObj newSO
throwIO (ErrorCall $ "Unable to resolve
objects for " ++ newSO)
-
looks at all undefined objects, makes sure all resolved, nothing is missing
-
c_sym line 157
c_sym <- lookupSymbol symName
h <- case c_sym of
Nothing -> do
-
assuming all resolved, can pull symbols out
-
purge vs unload- keep libraries but forget symbols you know about. This is so that when a new instance is called, it doesn’t conflict with old symbols
-
updateState… line 118
updateState mvar symbolName nextPath = do
newVal <- force <$> l
oadNewSO symbolName nextPath
-- Build a new state for this version
- if in middle of process, lock old state
Some complexities / things to think about
- sticky shared objects
- can’t persist data or code
- cap on shared object size
- forced calls (DeepSeq) - squashes all forms (not too clear on this)
- Haskell vs C…in Haskell, text is an object on the heap
Other discussions
- cross-boundary inlining (I need to look this up. I know what function inlining is)
- flag..keep haskell code in binary
Tikhon gave a talk on Programming with Probability
-
I had seen his talk at Compose Conference, so was interesting to see how he adapted it for more business-oriented audience (he was using us as his test audience for a presentation he had to give internally the next morning)
- Supply chain optimization is stochastic
- Target has 87 stores to be supplied by 37 supply centres
- Their job is to minimize total inventory while supplying stores. Thinking about things like spoilage, while keeping inventory on shelves.
There is an element of Demand uncertainty
- We don’t know what will sell, if any
- Probability Distributions needed
- sampling simulations (useful for where small sample size needed)
- exhaustive (where entire distribution is needed). Useful for applying domain-specific algorithms where specific data is needed
A probability can be thought of a map from set to weight, where the weights add up to 1
- So a probability is a map from
a -> b -
Therefore, distributions form a functor
- A die can be thought of a boolean operation
- If we take odds as 1 and evens as 0, we can map the value to a coin
- However, it becomes difficult to reverse this, as we lack information (two values to represent six). How then, do we add the “noise” back? He referenced a monadic bind operator
What we can do
- We have two dice
- We can take all the probabilities possible and then flatten them
-
We can also take a biased set of coins, for example, one that gives a probability of .1 for heads and .9 for tails and create with two of them, a tree of all possibilities. We can also then flatten or simplify that tree into just heads or tails
- He also discussed join and flat map with similar analogies
Ideas/ Things to think about
- This is not viable for long scaling of applications. When you flatten a probability graph, it may not accurately represent probability distribution
- there are models that are say, quadratic, that don’t fit
- there are languages with randomness built into them
He mentioned a paper
That’s about it
- We went out to Firehouse afterwards for food and drinks!
- I had about seven minutes between the time Caltrain arrived and the time I caught my bus back at San Jose Diridon. Tikhon was nice enough to keep an eye on the time for me. I also met Nick, from my FP Slack. He said he probably wouldn’t have even made it if I didn’t tell him about the Meetup. That was really nice of him! I had a blast, and man, the company was just wonderful! Left the Meetup with a smile on my face, and lots to think about!
Things this week
- I’m going to this Recruitment event tomorrow, or if not, my sailing Monthly meeting. It’s an invite-only event, so we’ll see.
- Have to work on C++ game. Ben (from my Haskell group) was really nice and said if I needed any assistance, to feel free to contact him! Means a lot; he’s awesome at C++, and I like getting beaten up by C++, and keep coming back for more! :)
- C++ exam…wrote up cheat sheet today (I need more practice on Operator overloading).
- Have to work on Google / Udacity coursework. My internet was a bit down today, but it’s back up, so….good timing
- Also, I finished my resume for this application that had very specific requirements. It was my first time writing an academic resume. Man, they have different interests. They care more about things like Publications and Presentations, which is interesting. I don’t have much of that, but hey, it’s something I can work on in the future! Right now, I’d like the opportunity and I’d like to continue coding. It’s the one thing I’d love to do for the rest of my life. I just have to get a professor recommendation and submit (fingers crossed).